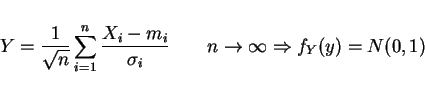Next: Random Processes
Up: Random Processes I
Previous: Probability space
CDF:
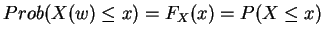
props
- 1.
-
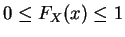
- 2.
- FX(x) is non decreasing
- 3.
-
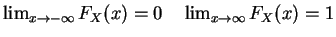
- 4.
- FX(x) is continuous from right
- 5.
-
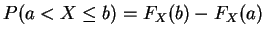
- 6.
-
P(X=a)=FX(a)-FX(a-)
pdf:
- 7.
-
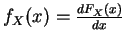 , if discrete we get impulses
props
, if discrete we get impulses
props
- (a)
-
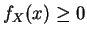
- (b)
-
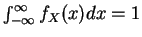
- (c)
-
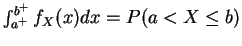
- (d)
-
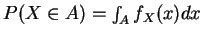
- (e)
-
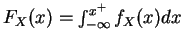
Useful RV distributions
- 1.
- Bernoulli: biasd coin flip
p - prob of success
1-p - prob of failure
- 2.
- Binomial (a sequence of N indept Bernoulli trials)
- 3.
- uniform
- 4.
- Gaussian
- 5.
- Poisson
- 6.
- Exponential
Functions of RV
no time to review here
But y=g(x) and fX(x) known,
first find
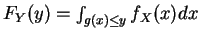
then differentiate
THIS ALWAYS WORKS! (book method doesn't always work)
More Defs
nth moment
nth central moment
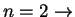 variance
variance
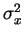
- 1.
-
E(cX)=cE(X)
- 2.
- E(c)=c
- 3.
-
E(X+c)=E(X)+c
- 4.
-
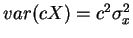
- 5.
- var(c)=0
- 6.
-
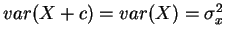
Characteristic functions
props
- 1.
-
- 2.
-
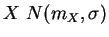 Gaussian
Gaussian
More than 1 RV, some basic idea
Look at props (top p.155)
Covariance
E((x-mX)(y-my))=cov(X,Y)
correlation coefficient
Turns out that
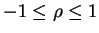 so its a nice measure of how correlated X+Y are.
so its a nice measure of how correlated X+Y are.
no corr. 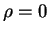 (not indept. necessarily!!!)
(not indept. necessarily!!!)
same RV 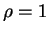 (only if Gaussian)
(only if Gaussian)
liar 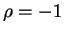
prop
- 1.
-
- 2.
-
Jointly Gaussian
2 vars
general
where
x=[x1 x2 ... xn]T
C = cov matrix,
|C|=det(C)
Props (Important since will mostly use gaussians)
- 1.
- any subset of jointly gaussian RV's is gaussian as well
- 2.
- completely characterized by their first and second moments
- 3.
- conditioning still makes them jointly gaussian
i.e.
fX1,X2|X3,X4 is jointly gaussian
- 4.
-
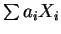 is gaussian. set of linear combos is gaussian
is gaussian. set of linear combos is gaussian
- 5.
- uncorrelated jointly gaussian RV's are INDEPENDENT
RV sums
- 1.
- Indept. RV's X+Y w/
fX(x), fY(y)
Prove it!
- 2.
- weak law of large numbers,
X1,X2,... uncorrelated each w/ mean mX and
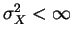 then
then
The empirical average converges in probability to the mean
- 3.
- Central limit thm.
X1,...,Xn indept. w/ means (
m1,...,mn) and (
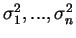 )
)
IID?
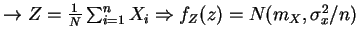 when
when
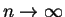
i.e. Large sums approach a gaussian!
Very useful since physical world is often a superposition of uncorrelated events!
Next: Random Processes
Up: Random Processes I
Previous: Probability space
1999-02-06
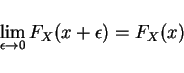
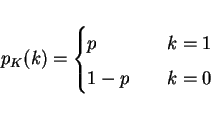
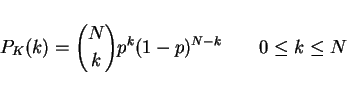
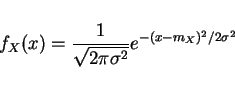
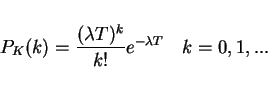
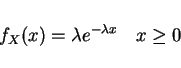
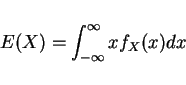
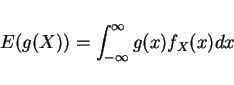
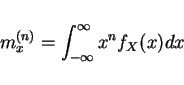
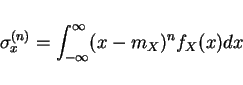
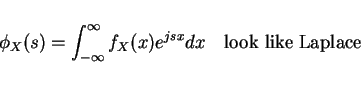
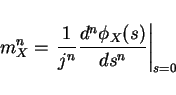
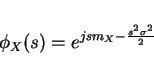
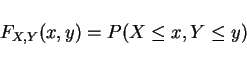
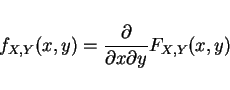
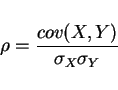
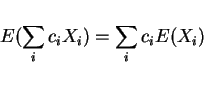
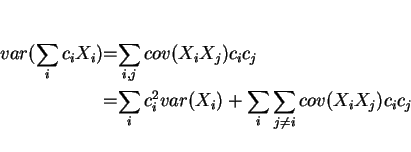
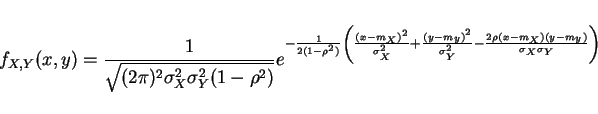
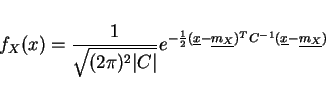
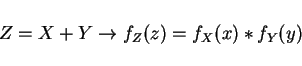
![\begin{displaymath}\epsilon>0, \lim_{n\rightarrow\infty} Prob\left[\left\vert\frac{1}{n}\sum_{i=1}^n X_i -m_X \right\vert > \epsilon \right]=0 \end{displaymath}](img65.gif)