Suppose we have a stochastic process X(t). Assume it's zero mean has correlation function RX(t1,t2)= [X(t1)X(t2)]. What we'd LIKE is to be able to represent X(t) as a superposition of orthonormal basis functions, scaled by independent random variables. The independence is a long shot. So what we'll DO is settle for uncorrelated projections on to the orthonormal basis functions.
So, we define
![]() with
with
![]() on some interval and require
the following:
on some interval and require
the following:
Note however, that we SEEM to have presupposed that
any old set of ![]() will do. NOT! (in general).
We require
will do. NOT! (in general).
We require
![]() ;
that
is, the ai are uncorrelated and have variances
;
that
is, the ai are uncorrelated and have variances ![]() (remember, that X(t) is zero mean therefore so are the ai).
(remember, that X(t) is zero mean therefore so are the ai).
Please also note that had the process not been zero mean, we could have defined the integral equation in terms of the covariance function E[(X(t1)-mX(t1))(X(t2)-mX(t2))] with the same result. However, since carrying the mean around often means (no pun intended) a headache, we assume ``centered'' random variables.
Here are some interesting factoids which we list without proof for the most part:
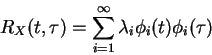
I'll continue this later, but want to get it out. Be wary of typos above. I'll provide the two examples we did in class in what follows.